
Honestly, when I need to write a quick and dirty script, my go-to language is Python. But the other
day, as I realized I needed to write yet another small web scraper, I decided to forego
Python’s BeautifulSoup
to instead take a look at
Go’s golang.org/x/net/html
package. Needless to say, it
is quite bare in comparison… But I also realized that it makes absolutely no concessions when it
comes to strictly following the HTML specification1.
Go is often simple, by no means simplistic and not always easy. It has a tendency to keep
abstractions at a minimum (an intentional choice of its creators2), which can be very confusing
to people coming from a more complex language (like Python). But less can be more: because Go does
very little effort to hide things away, it provides developers with plenty of opportunities to learn
about what other languages do not expose. This time is no different: I ended up learning a great
deal about HTML in general and table in particular, and figured I could share my findings in a
blog post.
A Surprising Parse Result
A little confession: when writing simple little scripts, I usually skip writing any kind of test, and simply try out my code as I go. Not a good practice, I know. But this time was to be different: I just finished reading The Pragmatic Programmer , which strongly advocates writing tests, and I decided I would write simple unit tests to check my code.
It so happens that my code contained logic working with table rows (the tr element). The code
looked like:
func parseRow(row *html.Node) {
if !(row.Type == html.ElementNode && row.Data == "tr") {
panic("this is not a row")
}
// Do some stuff
}
And so I wrote my unit test:
func TestParseRow(t *testing.T) {
raw := "<tr><td>1</td><td>2</td></tr>"
doc, _ := html.Parse(strings.NewReader(raw))
parseRow(doc)
}
Easy enough, right? I thought so too. And so I ran go test.
--- FAIL: TestParseRow (0.00s)
panic: this is not a row [recovered]
panic: this is not a row
Wait, what? How is this possible? After a little bit of debugging, I found out that the result of
Parse(string.NewReader(raw) was in fact a node that contained the following elements:
<>
<html>
<head>
</head>
<body>
12
</body>
</html>
</>
I was perplexed. Where are my tr and tds? I was expecting something like what Python returns:
from bs4 import BeautifulSoup
soup = BeautifulSoup("<tr><td>1</td><td>2</td></tr>", 'html.parser')
print(soup.prettify())
# this will print:
# <tr>
# <td>
# 1
# </td>
# <td>
# 2
# </td>
# </tr>
In short, to me, it looked like a bug in the Go HTML parser! But I held my horses, and resisted my
initial impulse to create an issue in the Go repository3. Instead, I played around a bit more, and
replaced the raw string in my test by "<table><tr><td>1</td><td>2</td></tr></table>". This
time, the Parse result was very different:
<>
<html>
<head>
</head>
<body>
<table>
<tbody>
<tr>
<td>
1
</td>
<td>
2
</td>
</tr>
</tbody>
</table>
</body>
</html>
</>
Aside from not really solving my problem, this brought more questions than answers. Why did the
parser ignore all tags in the first case but not when adding a table? Why did it add tags like
html, body or tbody? This is the moment I remembered that
golang.org/x/net/html
actually points towards the HTML
specification
, and I decided to take a look.
Doing so rewarded me with answers to my questions (spoiler: the Go HTML parser works perfectly fine), and allowed me to find a clean solution to my problem. But before showing the exact Go code that did the trick for me, I will first explain why these surprising results in fact show that the Go HTML parser is strictly following the HTML specification and working perfectly as intended. But if you have no interest in that or find yourself short on time, feel free to directly jump to the solution .
The Reason Why
I started browsing the HTML specification with two very simple questions in mind:
- Why is the parser generating extra tokens like
bodyortbody? - What explains the weird output when parsing
trandtdoutside oftable?
Optional Tags: Omitted, But Not Forgotten
I only have basic notions of HTML, but I vaguely remembered that some tags, like html, can be omitted when
writing a document. Yet, Go’s HTML parser seemed determined to generate those, even when they
were not explicitly present in the input string. Why bother with this extra work? I thought. Reading the first
few lines of the HTML syntax
page was very enlightening:
Documents must consist of the following parts, in the given order:
- Optionally, a single U+FEFF BYTE ORDER MARK (BOM) character.
- Any number of comments and ASCII whitespace.
- A DOCTYPE.
- Any number of comments and ASCII whitespace.
- The document element, in the form of an html element.
- Any number of comments and ASCII whitespace.
This means that a valid HTML document must contain a DOCTYPE, and that all subsequent tags have to be
enclosed in a mandatory <html></html> node. Besides, all normal elements (which is to say
pretty much all HTML nodes) have a content
model
, describing the requirements
that all children of said element must match.
In the case of the html element, the content model is very straight forward:
A head element followed by a body element.
In other words, the minimum viable HTML document holding content other than metadata is:
<DOCTYPE html>
<html>
<head>
</head>
<body>
<!-- content goes here -->
</body>
</html>
What about omitting tags then? This is of course possible, as the specification states in its optional
tags
section. But the key
takeaway from that section is that omitted tags are not absent: they are implied, but still here! And as
it turns out, html, head and body can all have their start and end tag omitted (assuming a few
conditions are satisfied).
It is the parser’s role to ensure that omitted tags are still present. The precise steps are
described here
, but in
short, generating tokens like html, body or head is part of Go’s HTML parser job: it is simply
ensuring that inputs are turned into viable HTML documents. In my case, the specification was also
dictating the generation of the tbody token, as the parsing algorithm is supposed to automatically
generate a tbody while encountering a tr in a table (outside of any other tbody, thead or
tfoot).
Eagle-eyed readers might have noticed that I am carefully leaving out the DOCTYPE. This is
because, to be honest, I am still unsure as to why the Go HTML parser does not add it nor complains
about its lack. Shouldn’t it do it, according to the specification? My best guess is that, since
DOCTYPE is there to indicate to browsers that the content following it is to be rendered as an
HTML document, the Go HTML parser does require it (it assumes the input is HTML anyway).
HTML and Parsing Errors
Optional tags are well and good, but what about the weird output I observed at first? How could the parser possibly transform this:
"<tr><td>1</td><td>2</td></tr>"
Into this?
<>
<html>
<head>
</head>
<body>
12
</body>
</html>
</>
While the result arguably appears counter intuitive to a HTML novice like myself, the parser is in
fact working exactly as intended. Unlike the table example, where the input was semantically
correct (although containing omitted tokens), the parser is this time supplied with an incorrect
HTML string. Like before, the parser will understand that tags are omitted, generate html, head
and body and parse the input assuming it is enclosed in <body></body> tags. But, according to
the specification, the body element’s content model only accepts flow
content
, which does not include
tr (nor td)!
To understand how the parser handles such parsing errors, I tried to follow the rules for parsing tokens.
- All tags up to
bodyare generated according to the rules of optional tags (the bottommost node of the tag stack is thusbody). - The parser encounters
tr, which is illegal in abodycontext. It ignores it. - The parser encounters
td, which is illegal in abodycontext. It ignores it. - The parser encounters the raw character
1, creates aTextnode whose data is “1”, and inserts it just afterbody. - The parser encounters
/td, which is illegal as the current node isbodyand nottd. It ignores it. - Same as 3.
- The parser encounters the raw character
2, but because there is aTextnode just before it, it appends “2” to that node’s data, turning theTextnode generated in 4. into aTextnode whose data is “12”. - Same as 5.
- The parser encounters
/tr, which is illegal as the current node isbodyand nottr. It ignores it.
The result of all these steps is a body node containing a Text node with “12”, which is exactly
the conclusion reached by the Go HTML parser. Working as intended :-)
Because an (animated) picture is worth a thousand words, I’ve created a GIF that shows what the parser does given a similar example:
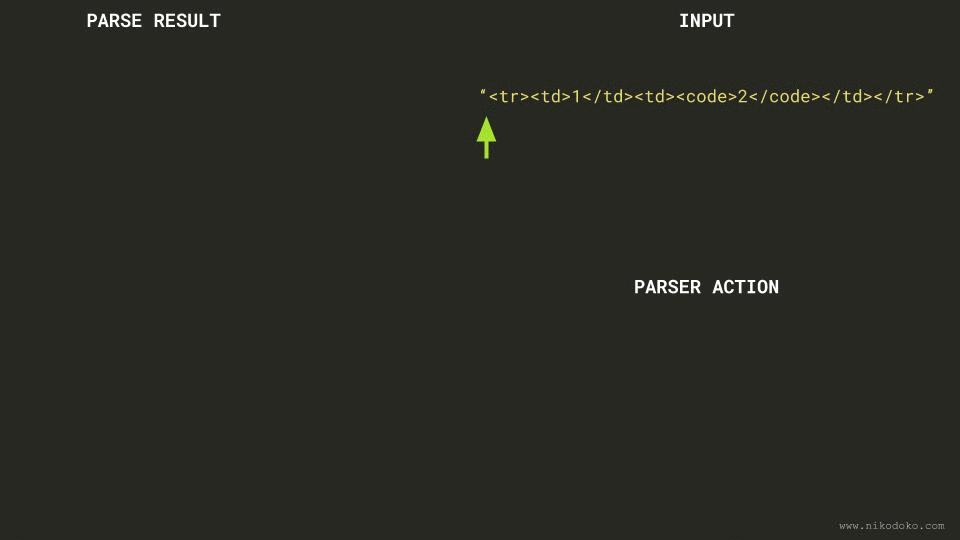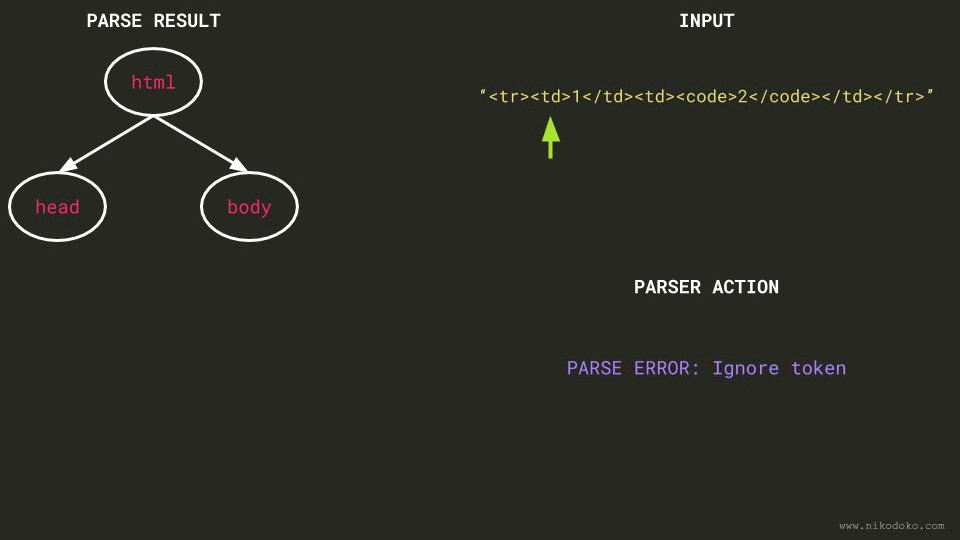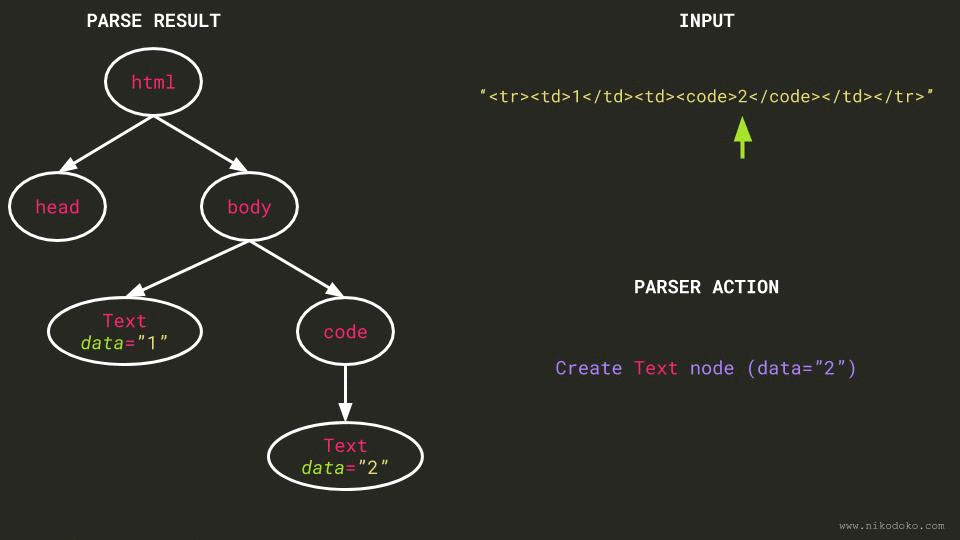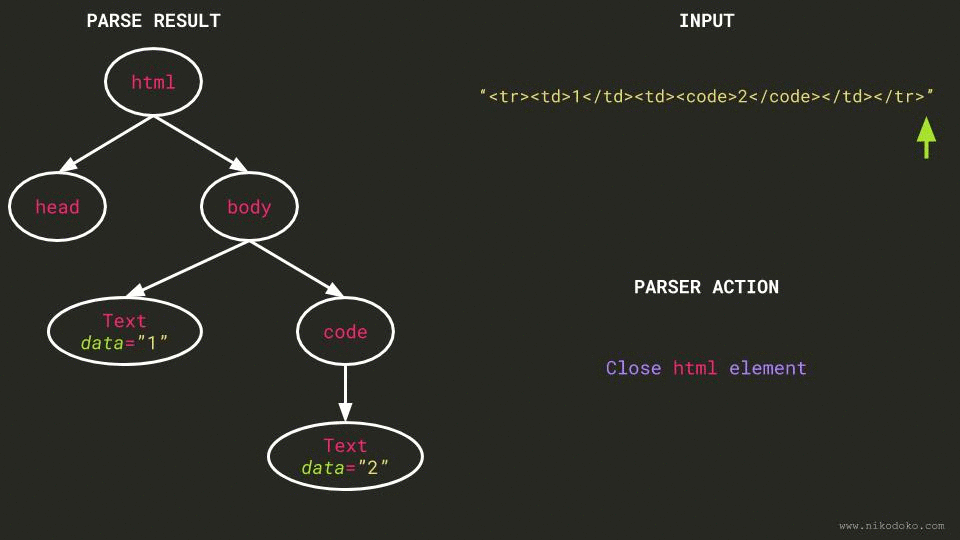
Solution
Back to my initial problem. How can I generate the following node architecture?
<tr data="2">
<td>
1
</td>
<td>
2
</td>
</tr>
The answer stems directly from the HTML spec I’ve detailed in the previous section
: such a sequence
can only exist in the context of a tbody. Given this, the only thing that has to be done is to
supply the Go HTML parser with the context in which it is to parse my fragment:
func TestParseRow(t *testing.T) {
raw := "<tr><td>1</td><td>2</td></tr>"
nodes, _ := html.ParseFragment(strings.NewReader(raw), &html.Node{
Type: html.ElementNode,
Data: "tbody",
DataAtom: atom.Tbody})
// Unlike Parse, ParseFragment can return multiple nodes,
// but we know that we can only have one here.
parseRow(nodes[0])
}
And that’s it! I think this little adventure with HTML tables embodies how the Go standard library, sometimes showing a frustratingly low level of abstraction, also provides opportunities to learn more. And in that sense, I feel like Go contributes to raising more knowledgeable software engineers4.
As always, shoot me a message or tweet @nicol4s_c if you want to chat about any of this, if you spotted any mistakes or typos, or if you’d like me to cover anything else! Have a great day :)
-
I am not being fair to Python as I am comparing a library built on top of
html.parserwhich is just as bare as Go’s parser. But my point about respecting the spec still stands. ↩︎ -
In Rob Pike’s own words, one of Go’s objectives was to avoid having “each programmer using a different subset of the language”, which naturally pushes towards simpler APIs (see this talk ) ↩︎
-
The Pragmatic Programmer says “if you see hoof prints, think horses, not zebras”: when encountering a bug, it is most likely not the library’s fault. ↩︎
-
Again, it is arguably one of it’s creators' goals, as Rob Pike says in this talk that Go was originally targeted at “typically, fairly young, fresh out of school” developers. ↩︎